Decoding "Attention Is All You Need" for Beginners
Created At: Jan. 24, 2025, 1:08 p.m.
Updated At: Jan. 24, 2025, 5:45 p.m.
A Step-by-Step Guide to Understanding the Attention Mechanism in Neural Networks
Introduction
Imagine a machine that can understand and generate human language with unprecedented fluency and accuracy, translating languages seamlessly, writing creative stories, and even answering your questions with insightful responses. This dream is becoming a reality thanks to a revolutionary concept in deep learning: the attention mechanism.
The "Attention Is All You Need" paper, introduced by Vaswani et al. in 2017, marked a turning point in the field of natural language processing (NLP) by presenting the Transformer model, a groundbreaking architecture that relies entirely on attention mechanisms. This model eliminated the need for traditional recurrent neural networks (RNNs), enabling faster training and achieving state-of-the-art results across a wide range of NLP tasks.
The Transformer's impact extends far beyond academia, powering many of the AI applications we use today, from chatbots and language translation tools to content creation assistants and cutting-edge research in areas like drug discovery. In this blog, we'll break down the "Attention Is All You Need" paper into simple terms and delve into the core concepts of the Transformer model, explaining the attention mechanism in a clear and accessible way. Let's demystify this groundbreaking paper together!
Background
Before the advent of Transformer models, attention mechanisms were incorporated into recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) to enhance their performance on tasks like machine translation.
These models, while effective, struggled with capturing long-range dependencies due to their sequential processing nature and the vanishing/exploding gradient problem. Attention mechanisms addressed this limitation by allowing the model to focus on the most relevant parts of the input sequence at each step.
This was achieved by calculating relevance scores for each word in the input sequence. These scores determined the weight given to each word when generating the output, effectively allowing the model to "pay attention" to the most important parts of the input.
By focusing on relevant information, attention mechanisms improved the accuracy of RNNs and LSTMs, particularly in tasks involving long sequences where capturing distant relationships between words was crucial.
The "Attention Is All You Need" paper, introduced by Vaswani et al. in 2017, revolutionized the field by proposing the Transformer model. This innovative architecture is fully based on attention mechanisms and eliminates the need for RNNs and convolutional neural networks (CNNs).
Key features of the Transformer architecture include:
- Parallel Processing: Transformers process input sequences in parallel rather than sequentially, leading to significantly faster training times and more efficient use of computational resources.
- Scalability: The architecture scales efficiently, allowing for the creation of larger models like GPT-3, which can handle vast amounts of data and perform complex tasks.
- Self-Attention: The self-attention mechanism enables the model to capture relationships between all words in a sequence, regardless of their distance from each other, improving the understanding of context and long-range dependencies.
- Multi-Head Attention: Transformers utilize multiple attention heads, allowing the model to capture different aspects of the input sequence simultaneously, enhancing the model's ability to understand nuanced relationships.
- Positional Encoding: Transformers use positional encoding to retain information about the order of words in a sequence, which is essential for tasks like translation and text generation.
This breakthrough demonstrated the power and versatility of attention mechanisms in modern deep learning models, setting new benchmarks in natural language processing (NLP) and other areas of artificial intelligence, such as computer vision.
Breakdown of the Paper
-
Abstract, Introduction, and Background:
Abstract:
The "Attention Is All You Need" paper introduces the Transformer, a novel neural network architecture that relies solely on attention mechanisms, eliminating the need for recurrent and convolutional networks. Experiments demonstrate that the Transformer achieves superior translation quality, is significantly more parallelizable, and requires substantially less training time compared to previous state-of-the-art models. The Transformer achieves state-of-the-art results on the WMT 2014 English-to-German and English-to-French translation tasks, with BLEU scores of 28.4 and 41.8, respectively. The model also demonstrates strong generalization capabilities on other tasks, such as English constituency parsing.
Introduction:
Traditional sequence modeling approaches, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), have been dominant in tasks like language modeling and machine translation. However, these models face limitations due to their sequential nature, hindering parallelization and efficiency, especially for longer sequences. Moreover, the vanishing/exploding gradient problem can limit their ability to learn long-range dependencies. Attention mechanisms were introduced to address these limitations by allowing the model to focus on relevant parts of the input data. The Transformer model, proposed in this paper, entirely relies on attention mechanisms, enabling significant parallelization and achieving new state-of-the-art performance in translation quality with reduced training time.
Background:
The motivation for reducing sequential computation has led to the development of models like the Extended Neural GPU, ByteNet, and ConvS2S, which utilize convolutional neural networks to compute hidden representations in parallel. However, these models face challenges in effectively capturing long-range dependencies due to the limitations of convolutional operations. The Transformer addresses this challenge by employing self-attention, which relates different positions of a single sequence to compute a representation of the sequence. Self-attention has been successfully used in various tasks, such as reading comprehension and text summarization. The Transformer is the first model to rely entirely on self-attention without using sequence-aligned RNNs or convolutions, offering significant advantages in parallelization and computational efficiency
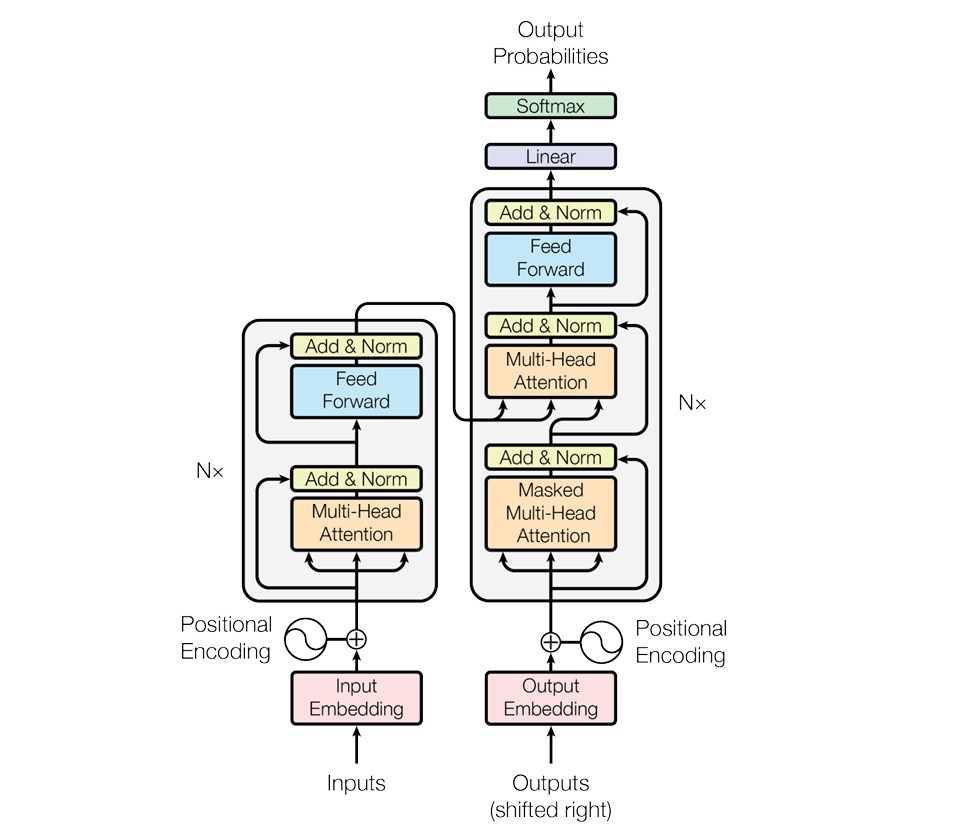
Model Architecture:
-
Encoder and Decoder Stacks:
Encoder
The encoder's primary role is to process the input sequence and generate a sequence of continuous representations. It consists of a stack of six identical layers, each containing two main sub-layers:
Multi-Head Self-Attention Mechanism: This sub-layer allows the encoder to focus on different parts of the input sequence by calculating attention scores for each word pair. This is achieved by computing a set of "queries," "keys," and "values" for each word, and then calculating attention scores based on the similarity between queries and keys. The multi-head aspect means that multiple sets of attention scores are computed in parallel, capturing various relationships and dependencies.
Position-wise Feed-Forward Network: This is a fully connected feed-forward network that processes each position of the input sequence independently and identically.
Each sub-layer in the encoder employs a residual connection around it, followed by layer normalization. This means the input to each sub-layer is added to its output before normalization, helping to mitigate issues like vanishing gradients and enabling faster training.
Decoder
The decoder generates the output sequence one element at a time, relying on the encoder's continuous representations. Like the encoder, the decoder also consists of a stack of six identical layers, but it has an additional sub-layer:
Masked Multi-Head Self-Attention Mechanism: Similar to the encoder, but with a modification that prevents positions from attending to subsequent positions. This is achieved by masking the attention scores for future positions, ensuring that the predictions for each position only depend on known outputs at earlier positions. For example, when translating the sentence "I love learning" step-by-step, the masked attention mechanism ensures that when predicting the word "love," the model only considers "I" and not the future word "learning." Similarly, when predicting "learning," the model focuses on "I" and "love" but does not look ahead to any future words.
Encoder-Decoder Attention Mechanism: This sub-layer performs multi-head attention over the encoder's output, allowing the decoder to focus on relevant parts of the encoded input sequence when generating the output.
Position-wise Feed-Forward Network: This is the same as in the encoder, processing each position separately and identically.
As with the encoder, each sub-layer in the decoder also uses residual connections and layer normalization.
Positional Encoding
Since Transformers process the input in parallel, they need a mechanism to incorporate positional information. Positional encoding is added to the input embeddings, providing information about the position of each word in the sequence, enabling the model to understand word order. This is done using sine and cosine functions to generate unique positional encodings that are added to the word embeddings. For example, for the sentence "I love learning," the positional encodings help the model understand that "I" is the first word, "love" is the second, and "learning" is the third, ensuring the correct word order in the input sequence